0. Abstract
머신러닝 모델은 일반적으로 학습 이후 고정된 상태로 배포되며, 테스트 단계에서는 더 이상 모델이 변화하지 않는다는 가정을 전제로 한다.
그러나 실제 환경에서는 학습 데이터와 테스트 데이터 간 분포 차이(distribution shift)가 빈번하게 발생하며, 이는 모델 성능 저하의 주요 원인이 된다.
2026년 기준 최신 연구 흐름에서는 이러한 문제를 해결하기 위해 Test-Time Adaptation(TTA) 기법이 다시 주목받고 있다.
본 논문은 테스트 단계에서 라벨 없이 입력 데이터의 분포를 분석하고, 출력 및 내부 표현을 재보정(recalibration)함으로써 모델의 일반화 성능을 유지하는 방법을 제안한다.
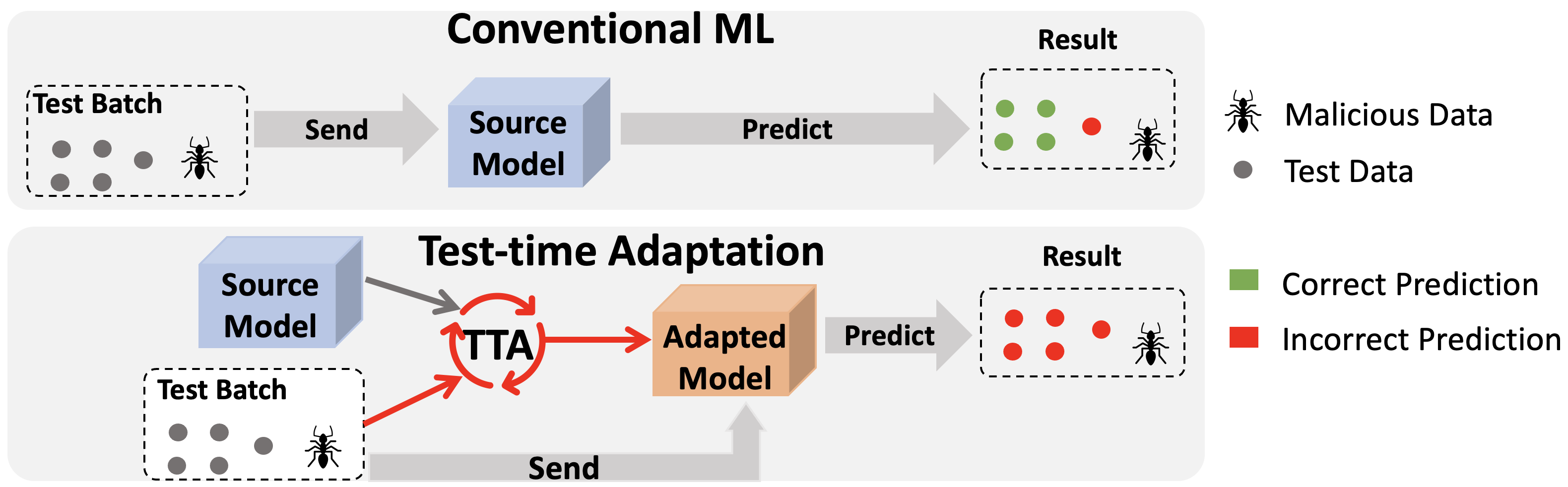


1. 문제 배경: Distribution Shift의 현실성
머신러닝 모델은 보통 다음과 같은 가정을 기반으로 학습된다.
- 학습 데이터와 테스트 데이터는 동일한 분포를 따른다
- 테스트 단계에서는 모델 파라미터를 변경하지 않는다
하지만 실제 환경에서는 다음과 같은 변화가 지속적으로 발생한다.
- 시간 경과에 따른 데이터 특성 변화
- 센서·입력 조건의 변화
- 사용자 행동 패턴 변화
- 노이즈 증가 또는 품질 저하
이러한 변화는 모델의 예측 신뢰도를 떨어뜨리며, 재학습 없이 해결하기 어려운 문제로 이어진다.
2. 기존 접근 방식의 한계
기존의 대응 방식은 주로 다음과 같았다.
- 새로운 데이터 수집 후 재학습
- 데이터 증강을 통한 일반화 성능 강화
- 도메인 적응(domain adaptation) 기법 적용
그러나 이 방식들은 모두 사전 대응 또는 사후 재학습에 가깝다.
즉, 모델이 배포된 이후 실시간으로 변화에 대응하기에는 비용과 시간이 많이 든다.



3. Test-Time Adaptation의 핵심 개념
Test-Time Adaptation은 문제를 다음과 같이 재정의한다.
테스트 시점에서도, 모델은 입력 데이터로부터 적응 신호를 얻을 수 있다.
TTA의 핵심 전제는 다음과 같다.
- 테스트 데이터에는 정답 라벨이 없다
- 하지만 입력 분포 자체는 중요한 정보를 포함한다
- 이 정보를 활용해 모델의 예측을 안정화할 수 있다
즉, TTA는 라벨 없는 온라인 적응을 목표로 한다.
4. 2026년 최신 접근: Distribution-Aware Recalibration
2026년 연구 흐름에서 주목받는 방향은
모델 파라미터를 직접 업데이트하는 방식이 아니라,
출력 분포 및 내부 activation 분포를 재보정하는 구조적 적응 방식이다.
이 논문은 다음과 같은 전략을 사용한다.
- 테스트 입력에서 관측되는 분포 통계 추정
- 예측 확률 분포의 과도한 편향 완화
- 채널별 activation 분포를 분위수(quantile) 기반으로 재조정
이 접근은 평균·분산 수준의 단순 통계 보정보다,
분포의 형태 자체를 반영한다는 점에서 기존 방법과 차별화된다.


5. 작동 방식 요약
제안된 TTA 방식은 다음 흐름으로 작동한다.
- 테스트 입력 수집
- 내부 표현(activation) 및 출력 분포 분석
- 분포 편차에 따른 보정 계수 계산
- 보정된 예측 결과 출력
중요한 점은 이 과정에서 모델의 주된 가중치는 고정된다는 것이다.
따라서 과적합이나 누적 오류 위험을 줄일 수 있다.
6. 실험 결과 요약
논문에서는 다양한 분포 변화 시나리오에서 실험을 수행했다.
- 입력 노이즈 증가
- 클래스 비율 변화
- 환경 조건 변화
그 결과, 기존 TTA 방식 대비
- 더 안정적인 성능 유지
- 작은 배치 환경에서도 일관된 개선
을 확인할 수 있었다.

7. 결론
본 논문은 Test-Time Adaptation을
“테스트 단계의 임시 보정”이 아니라
분포 인식 기반의 구조적 적응 문제로 재정의한다.
2026년 기준 머신러닝 연구 흐름은
모델을 더 크게 만드는 방향보다,
환경 변화에 얼마나 안정적으로 대응할 수 있는가에 초점을 맞추고 있으며,
본 기법은 그 흐름을 잘 보여주는 사례라고 볼 수 있다.
8. 개인적인 느낀점
이 논문이 인상적인 이유는,
머신러닝 모델을 “완성된 결과물”이 아니라
환경에 반응하는 시스템으로 다시 바라보게 만든다는 점이다.
앞으로 장기 운영되는 머신러닝 시스템에서는
학습 성능보다도 유지 성능(robustness)이 더 중요해질 가능성이 크며,
Test-Time Adaptation은 그 중심에 놓일 개념이라고 느껴졌다.